

Neulich bin ich auf einen Artikel im Netz gestoßen, der über die Verurteilung eines Doppelmörders in den USA berichtete, auf dessen Spur man über 30 Jahre nach der Tat mithilfe der DNA-Genealogie gekommen war. Meine Freude darüber, dass dieses Thema endlich mehr Aufmerksamkeit in Deutschland findet, war nach einem Blick auf die Kommentare jedoch schnell getrübt. Kaum jemand äußerte sich positiv über diese neue Art alte Verbrechen aufzuklären, an denen die Ermittler mit gewöhnlicher Polizeiarbeit sich jahrzehntelang die Zähne ausbissen, die es aber nun – in einzelnen Fällen nach nur wenigen Stunden Recherche – ermöglicht, einen Schwerstverbrecher doch noch für seine grausamen Taten zur Rechenschaft zu ziehen.
Unter den zahlreichen negativen Kommentaren fanden sich Skeptiker, die so eine Methode gar nicht erst für möglich hielten und die Ergebnisse als solche anzweifelten. Dann gab es Leute, die gleich den Teufel an die Wand malten und von der totalen Überwachung durch den Staat und Geheimdienste sprachen. Nach Lesern, die sich für die Familien der Opfer freuten, denen auf diese Weise wenigstens etwas Gerechtigkeit widerfuhr, suchte ich leider vergeblich.
Mir wurde schnell klar, dass die meisten dieser Menschen vor allem eins verbindet: die Unwissenheit darüber, wie man eigentlich bei der Suche mittels der DNA-Genealogie vorgeht und eben die Angst, die durch dieses Unwissen ausgelöst wird. Deshalb hoffe ich, mit meinem Beitrag etwas Licht ins Dunkel zu bringen und anhand eines realen Beispiels einen Einblick in die Welt der DNA-Genealogie zu gewähren.
Nun habe ich natürlich keine Tatort-DNA eines mutmaßlichen Serienmörders zur Hand, die ich bei GEDmatch einspeisen könnte. Deshalb weiche ich auf die DNA-Daten einer zweiten Personengruppe aus, die sich derselben Vorgehensweise bedient, um etwas über ihre genetische Herkunft zu erfahren: die Adoptierten.
Shelley (alle Namen wurden verändert) hat ein Leben lang erfolglos nach ihren Wurzeln gesucht. Die Adoptionsakte, die sie als Volljährige einsehen konnte, enthielt ausschließlich nicht identifizierende Informationen über ihre biologischen Eltern, und was sie auch versucht hatte, mehr war über sie einfach nicht herauszubekommen. Als sie 2018 einen DNA-Test bei MyHeritage machte und die DNA-Rohdatei u.A. auch bei GEDmatch hochlud, ahnte sie nicht, wie schnell sich das ändern würde.
Ich selbst erfuhr nur zufällig von Shelley durch unsere gemeinsame Verwandte, Noemi. Noemi ist eine entfernte Cousine 4. Grades, auf die ich vor ein paar Jahren im Internet aufmerksam wurde, weil wir nach denselben Vorfahren suchten. Etwas später entdeckten wir uns auch gegenseitig auf der Verwandtschaftsliste bei FTDNA und blieben seitdem in Kontakt. Während eines Skypegesprächs letztes Jahr erzählte sie mir aufgeregt, dass sie vor wenigen Tagen von einem unbekannten, aber sehr nahen DNA-Treffer über GEDmatch kontaktiert wurde. Nachdem die Frau ihr ihren Geburtsort mitgeteilt hatte, habe sie sofort den Verdacht gehabt, dass eine ihrer Cousinen mütterlicherseits die leibliche Mutter des DNA-Treffers sei. Diese Cousine habe ihr gegenüber soeben tatsächlich zugegeben in ihren jungen Jahren ein Kind zur Adoption freigegeben zu haben. Sie habe Noemi erlaubt Informationen über sie an ihre adoptierte Tochter herauszugeben, ein Treffen jedoch abgelehnt, weil sie Zeit brauche, um nachzudenken. Sie habe ihrem Mann und ihren Kindern nie von ihrem ersten Kind erzählt und möchte ihr Familienleben nicht gefährden. Über den biologischen Vater wisse sie nichts, da es sich dabei um eine flüchtige Bekanntschaft während einer Party gehandelt haben soll.
Ich war von der Geschichte augenblicklich fasziniert und loggte mich nach dem Gespräch sofort bei GEDmatch ein, um mir die Verwandtschaftsliste von Noemi anzuschauen. Es wurde mir sofort klar, dass die Rede von Shelley Rogers gewesen sein musste. Ihr Name tauchte auf Noemis Verwandtschaftsliste direkt nach Walter, ihrem Onkel mütterlicherseits, auf. Dann klickte ich auch auf Shelleys Verwandtschaftsliste. (Mit Verwandtschaftsliste meine ich hier die Anwendung One-to-many comparison.) Diese sah so aus:

ERSTER SCHRITT – EINSCHÄTZUNG DER VERWANDTSCHAFTSBEZIEHUNGEN
Auf der Verwandtschaftsliste bei GEDmatch schaut man als erstes auf die Spalte mit der cM-Angabe, die es einem ermöglicht, die aufgelisteten DNA-Treffer einer Person in Bezug auf ihren Verwandtschaftsgrad einzuschätzen. Shelleys höchster DNA-Treffer war Walter mit 823.8cM, der damit in die Kategorie der Verwandtschaftsbeziehungen mit etwa 12,5% identischer DNA fiel, also z.B. Cousin 1. Grades oder Großonkel. (Die durchschnittlichen Verwandtschaftswerte kann man in der Bettinger-Tabelle nachschauen https://dnapainter.com/tools/sharedcm.) Nach der Einschätzung der Verwandtschaft mit den DNA-Treffern, weiß man wie weit zurück man den Stammbaum ausbauen sollte, um den gemeinsamen Vorfahren zu finden. Danach baut man den Stammbaum wieder zurück in die Gegenwart, um die Zielperson zu identifizieren.
Da ich in diesem Fall bereits wusste, dass Walter der Onkel mütterlicherseits von Noemi war und Shelley die Tochter einer ihrer Cousinen, erstellte ich einen kleinen Stammbaum für Shelley:
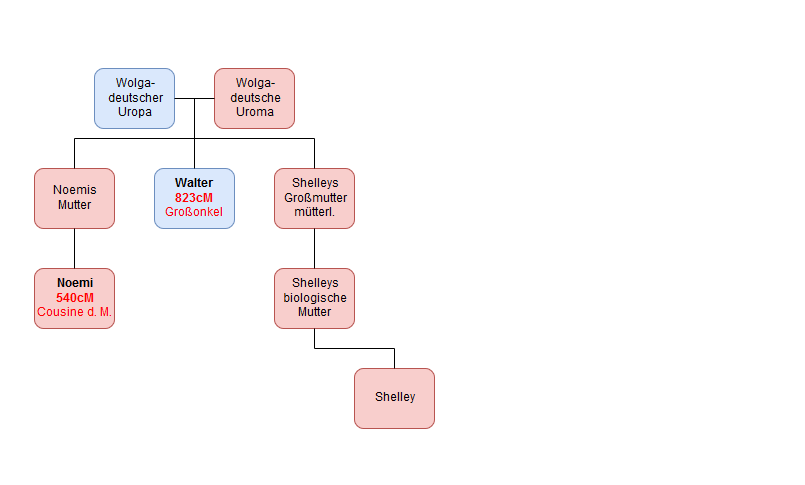
Außer Walter und Noemi hatte Shelley aber noch weitere gute DNA-Treffer – Catherine mit 561cM und Devon mit 388cM – die nicht mit den beiden anderen verwandt waren. Catherine schien in einer ähnlichen Beziehung zu Shelley zu stehen wie Noemi (Cousine eines Elternteils) und Devon eine Generation weiter weg. Würden Catherine und Devon mir dabei helfen können, etwas über den unbekannten biologischen Vater von Shelley herauszufinden?
ZWEITER SCHRITT – GENETISCHE CLUSTER ERSTELLEN
Im nächsten Schritt machte ich mich daran, Shelleys DNA-Treffer bei GEDmatch verschiedenen Gruppen zuzuordnen. Zunächst sollte man die genetische Verwandtschaft in die mütterliche und die väterliche Linie aufteilen, dann nach Möglichkeit auch in mehrere der weiter zurückliegenden Vorfahrenlinien. Wenn sich nämlich zusätzliche Informationen über eine Person aus der Gruppe finden lassen (über einen eingestellten Stammbaum, die Find A Grave-Webseite, Volkszählungen oder Facebook), lassen sich alle anderen Treffer in der Gruppe sehr viel leichter in das Gesamtbild einordnen.
Hierzu benutzte ich die Anwendung Auto-Clustering und bekam folgendes Ergebnis:

Die näheren Treffer von Shelley konnte man in drei verschiedene Gruppen einteilen. Da ich bereits wusste, dass die erste Gruppe mit Shelley durch die Großmutter mütterlicherseits verwandt war, konzentrierte ich mich auf die grüne Gruppe mit Catherine und Devon. Um sicher zu gehen, dass es sich dabei um Verwandte auf der Seite ihres biologischen Vaters handelte und nicht um die des Großvaters mütterlicherseits, benutzte ich die Anwendung One-to-one comparison. Zuerst verglich ich Shelley mit Walter und fand die Segmente auf den Chromosomen 2 und 3 dabei besonders interessant:
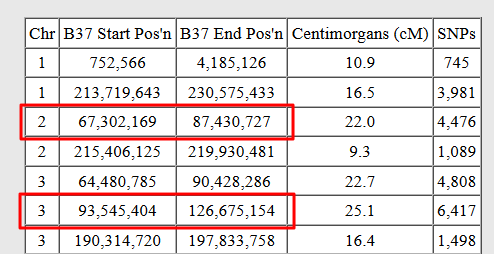
Denn an diesen Stellen gab es auch zwischen Shelley und Catherine Übereinstimmungen:

Da Walter und Catherine nicht miteinander verwandt waren, musste es sich hier um zwei verschiedene Chromosomenkopien von Shelley handeln. Auf diese Weise ließ sich zweifellos feststellen, dass Catherine und die anderen Mitglieder des grünen Clusters mit Shelley über die Linie ihres biologischen Vaters verwandt waren.
Ich legte für Shelley ein DNAPainter-Profil an, wo man das Ganze etwas übersichtlicher sehen konnte:

SCHRITT DREI – INTERNETRECHERCHE
Der grüne Cluster bestand aus fünf Personen und nun galt etwas mehr über sie herauszufinden – dem Einfallsreichtum sind hier keine Grenzen gesetzt. Man googelt öffentliche Nachrufe, versucht es in sozialen Netzwerken, aber vor allem setzt man auf die Datenbanken von Ancestry, FamilySearch, FindMyPast (besonders geeignet für Personen britischer Herkunft) und MyHeritage, da diese neben verschiedenen Dokumenten und Volkszählungen über großangelegte Stammbäume verfügen. In der Regel hat man in der heutigen Zeit schnell Erfolg, solange es sich nicht um jemanden mit dem Nachnamen Jones, Miller oder Smith handelt. (Wenn ein Serienmörder gesucht wird, stehen den Ermittlern natürlich zusätzlich Polizeidatenbanken zur Verfügung.)
In Shelleys Fall reichte aber schon Google vollkommen aus. Denn einer der fünf Personen aus dem grünen Cluster, Devon, stellte sich als ein echter Glückstreffer heraus. Er hatte keinen gewöhnlichen Namen und beschäftigte sich außerdem seit Jahren mit der Ahnenforschung (bei Facebook war er auch), so dass ich relativ schnell seinen Stammbaum gefunden habe. Dem Stammbaum konnte ich den gemeinsamen Vorfahren von ihm und Catherine entnehmen und darüber hinaus den Rückschluss ziehen, wer die Urgroßeltern von Shelley waren. Außerdem stellte ich fest, dass John der Sohn von Devon war, als ich mir seine Verwandtschaftsliste anschaute. Mit 3582cM identischer DNA, mussten sie in einer Vater-Sohn-Beziehung zu einander stehen. Da John aber weniger gemeinsame DNA mit Shelley teilte als Devon, musste er der Sohn von Devon sein und nicht umgekehrt.
So sah Shelleys Stammbaum nach der Erweiterung aus:

Es stellte sich heraus, dass Catherine die Enkelin von Philomene LaVallee und Robert Frampton Lee war und Devon der Enkel von Philomene LaVallee und einem anderen Mann aus der Nachbarschaft. Insgesamt hatte Philomene neun Kinder und zwei von ihnen konnten als Großmutter und Großvater von Shelley somit ausgeschlossen werden. Bei den übrigen sieben handelte es sich um sechs Söhne und eine Tochter. Aus der Auswertung der Ergebnisse konnte man schließen, dass Shelleys Großvater oder Großmutter väterlicherseits und Catherines Mutter Vollgeschwister gewesen sein mussten.
Ich machte damals einen Screenshot von Shelleys Stammbaum und schickte ihn an Noemi mit der Bitte, diesen an Shelley weiterzuleiten. Doch Devon, der begeisterte Ahnenforscher, entdeckte Shelley ebenfalls auf seiner Verwandtschaftsliste und kam mir zuvor. Da er die Namen und Daten sowohl von allen sieben Kandidaten als auch von ihren Nachkommen hatte, hätten diese kontaktiert und um eine DNA-Probe gebeten werden können. Doch das wäre Shelleys Entscheidung. Es war für mich absolut verständlich, dass sie die neuen Informationen erst einmal für sich verarbeiten wollte. Innerhalb kürzester Zeit hatte sie Kontakt zum relativ nahen familiären Umfeld ihrer biologischen Eltern und erfuhr u.A. die Namen von vier ihrer Urgroßeltern. Darüber hinaus auch von ihren wolgadeutschen (ein Viertel) und indianischen Wurzeln (ein Achtel).
Wenn Shelley ein gesuchter Verbrecher gewesen wäre, würde man auch mit Shelleys anderen, etwas weiter entfernten DNA-Treffern arbeiten. Es gab ja noch einen anderen, roten Cluster, der zu einem anderen Großelternteil hätte führen können und somit zu weiteren Hinweisen, von welchem der sieben Kandidaten der biologische Vater von Shelley abstammte. Allerdings wäre das etwas komplizierter zu erklären und daher ein Thema für einen eigenständigen Beitrag. Je nach Situation hätten auch andere Tools eingesetzt werden können, wie z.B. das von Dr. Leah Larkin entwickelte WATO-Tool. Sollte unter Shelleys DNA-Treffern irgendwann eine Frau mit etwa 25% identischer DNA und einem identischen X-Chromosom auftauchen, wären die beiden wahrscheinlichsten Möglichkeiten, dass es sich dabei entweder um eine andere Tochter ihres biologischen Vaters handelte oder um ihre Großmutter väterlicherseits, was sich aber leicht herausfinden ließe, sobald man diese Person auch mit Catherine und Devon vergleichen würde.
EIN PAAR WORTE ZUM SCHLUSS
Zum Schluss möchte ich erwähnen, dass die Arbeit eines DNA-Genealogen ausschließlich auf logischen Schlussfolgerungen basiert und die Ergebnisse deshalb von jedem anderen DNA-Genealogen auf ihre Richtigkeit hin überprüft werden können. Des Weiteren besteht die Arbeit eines DNA-Genealogen nur darin, die Identität eines Unbekannten durch die Erstellung von Stammbäumen anhand eines Vergleichs mit anderen Personen in der Datenbank festzustellen. Dass diese DNA-Probe einem mutmaßlichen Mörder gehört, stellen nur die in der Kriminalistik erfahrenen Ermittler fest. Außerdem werden den Polizeibehörden bei GEDmatch Grenzen gesetzt – so steht jedem Nutzer die Möglichkeit zu, sein DNA-Profil (und natürlich alle anderen, die er verwaltet) für polizeiliche Ermittlungen zu sperren.
Seit April 2018 wird im Durchschnitt einmal in der Woche ein Cold Case in den USA gelöst. Es handelt sich dabei um Fälle von unvorstellbarer Grausamkeit, Mord und Vergewaltigung – sehr oft richteten sich diese Gewalttaten gegen Kinder. Wäre es denn wirklich so schlimm, wenn auch ein deutscher Serienmörder, der viele Jahre ungeschoren davongekommen war, sich doch noch für seine grausamen Taten verantworten müsste?
Und wäre es denn so schlimm, wenn eine adoptierte Person Antworten über ihre Herkunft erhalten würde? In manchen Fällen wäre es eine Wiedergutmachung für die Vergangenheit. Beispiele in der deutschen Geschichte gäbe es genug – Zwangsadoptionen in der DDR, Kinder aus den Lebensborn-Heimen oder auseinander gerissene jüdische Kinder, die heute 80-90 Jahre alt sind und sich immer noch fragen, ob ihre Geschwister damals überlebt haben?
Letztes Update erfolgte am 22.04.2026. Links zu Webseiten Dritter oder Facebook-Gruppen wurden vorsichtshalber entfernt.
Hut ab,
du hast ein „schweres“ Thema nett verpackt und sehr anschaulich geschrieben.
Vielen Dank
Vielen Dank! Dieses Thema liegt mir sehr am Herzen.
Hallo Frau Haas,
das ist wirklich eine sehr umfangreiche und verständliche Darstellung. Hut ab! Auf Ihrer Seite habe ich interessanterweise auch die Verbindung zu Wogadeutschen gesehen und Sie nennen dort eine wichtige Quelle. Besitzen Sie das Buch von Igor Pleve „Einwanderung in das Wolgagebiet 1764-1767“? Wenn ja, ließe es Ihre Zeit zu, dort einmal nach meinem Familiennamen Quiring zu schauen? Es geht u.a. um Emanuel Quiring, dessen Eltern Jonas Quiring aus Fresenheim und seine Frau Anna Katharina geb. Jacoby. Ich wäre Ihnen sehr dankbar und verbleibe
mit freundlichem Gruß
Peter Quiring aus Dortmund
Hallo Herr Quiring,
bei Fresenheim handelt es sich um eine sogenannte „Tochterkolonie“, die erst 1860 von Mennoniten aus Preußen gegründet wurde. An Ihrer Stelle würde ich nach weiteren Informationen deshalb nicht im Buch von Prof. Dr. Igor Pleve suchen, sondern in einem anderen: „Die Auswanderung der Mennoniten aus Preussen 1788-1870“, welches von ihrem Namensvetter Dr. Horst Quiring geschrieben wurde. Darüber hinaus finden Sie noch bei Karl Stumpp einige Informationen über die Auswanderung der Mennoniten mitsamt einer Namensliste. Dort werden acht Quiring-Familien aufgelistet – bei welcher es sich um Ihre Vorfahren handelt, kann ich Ihnen aber natürlich nicht sagen.
Ich hoffe, dass ich Ihnen hiermit weiterhelfen konnte!
Klasse! Genau so eine Beschreibung habe ich gebraucht. Sehr anschaulich! Vielen Dank!
Vielen Dank, das freut mich sehr!
Ich habe mir ein Lesezeichen gesetzt, ich bin zu später Stunde auf Ihre Seite gekommen. Muss mir Zeit nehmen um diese Seite von vorne bis hinten zu lesen;)
Herzlich willkommen auf meiner Webseite!
Für mich als Anfänger mit der Erforschung von Vorfahren über DNA außerordentlich hilfreich. Sehr anschaulich und auch nachvollziehbar erklärt. Vielen Dank und freundliche Grüße aus dem Schwarzwald.
Vielen Dank für Ihr freundliches Feedback! 🙂